

Hot Product
Software Architecture Style (Update 08/2024)
Objective:
- Objective of this write up is to give new joiners high level overview of architecture at Vatico. This high level architecture also helps new joiners to understand what kind of common issue will have in each architecture, so if it happens they know roughly why and who to contact.
- Second objective is to showcase the design principle, which is to attract the right types of new joiners. Another aspect is for new joiners to understand the design principle of each pipeline. For example, you are building a vat for warranty.
Scope:
- Software architecture styles for Vatico infrastructure
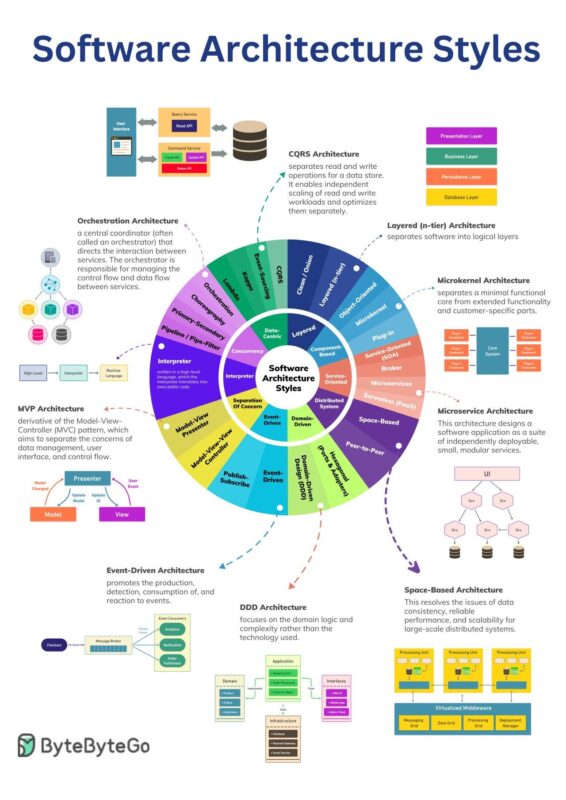
CRM
MVC Architecture
- Purpose: Achieves near-real-time responsiveness.
- Features: Manages interactions via Model-View-Controller (MVC) pattern, ensuring efficient data handling and UI rendering.
- Benefit:
- Separate of concerns: model, view and controller are separated in terms of functionality, hence easier to maintain
- Scalable: a same model can have different views, allowing faster analysis and easier to add views
Problem:
- The main issue with the MVC (Model-View-Controller) design pattern is that it demands careful initial planning. If the initial design is flawed, fixing it later can be very costly. For instance, in an early version of an order system, you might include the SKU directly in the order model. Later, you realise it should be in an order item model, requiring a major refactor. This mistake necessitates extensive redevelopment, involving changes to the database, code, and user interfaces. Therefore, poor initial design in MVC can lead to high long-term costs.
Fulfilment
Orchestration (Batch Process)
-
- Purpose: Ensures large scale and robust data interaction across services.
- Features:
- Low uptime (90%) compared to stream pipeline (99%)
-
- transform data for other applications (like sending data to post call, …).
- Requires high throughput and precision, with high tolerance for errors.
- Utilises Directed Acyclic Graphs (DAGs) to define and manage the sequence of tasks, ensuring tasks are executed in a specified order and dependencies are properly managed. This also allow one error to not stopping the whole operation
- Supports updates that are not real-time but can afford short delays (30 min – 1 hr). However, there are self-correcting mechanisms for failed updates, enhancing reliability, typically after one cycle.
Planned
Event-driven (Stream)
-
- Purpose: Suitable for time-sensitive information, providing real-time data processing.
- Features:
-
- Requires highly precise engineering.
- Significantly reduces lag compared to traditional orchestration.
- Ideal for applications where timing and responsiveness are critical. For example Lazada orders require fast fulfilment time or infrastructure downtime trackers that enforce downtime to be as low as possible.
- Kafka: Failed events can be replayed, meaning that while this ensures 100% of events are processed
Problem:
- Kafka: it may result in duplicate processing or increased complexity in handling retries and ensuring data consistency. Requires data contract
- Continuous data streaming can lead to higher operational costs. Another option besides Kafka is AWS Kinesis Firehose, which offers a fully managed service for real-time data streaming. It can be significantly more costly compared to Kafka, especially for large-scale deployments.
- Managing data consistency and integrity in real-time can be difficult.
- Dependencies between events can cause issues
Data Warehouse
Layer
Raw and transformed data are segregated into different layers, such as raw data in staging schema and transformed data in report schema
Allow for a clear separation of duty
- Error in the staging (EL) layer, DE will be the one to fix it,
- Error in the reporting (T) layer, DA will be the one to fix it
Allows Vatico to effectively upscale as work becomes more complex.
Cons
- Coordination Challenges: Different teams handling different layers can face difficulties in communication and collaboration, causing delays in fixing issues.
- Maintenance Difficulties: As the system grows, keeping layers organised and efficient becomes harder, requiring more effort to maintain.
- Increased Complexity: Managing multiple data layers adds complexity, requiring more oversight and specialised knowledge.
- Longer Processing Times: Moving data through several layers can slow down the overall processing, delaying data availability and increasing data cycle time.
Orchestration
Using Jinja to reference different models so that models can be executed in sequence of dependence, ensuring proper lineage tracking and maintaining the order of execution based on their dependencies.
- For Eg. Table B needs data from Table A, so Table A will be executed first)
Sequential Mechanism (Current)
- After data pipelines, we run API commands to be able to generate sales order and shipments
- The process is done step by step and very easy to understand
- However, if one step fails, the whole system fails. This is very prone to error as we relied on 3rd party API, which is not consistent.
DAG Mechanism (Road map to slowly transition to)
- Put tasks in to a DAG
- Continues running even if some tasks fail. Then it can retry separately
- Runs tasks in parallel.
- Easier to handle complex workflows.
Domain Driven Design (DDD)
- Transform data into different business domains
- Business logic required in these models are complex, thus by organising models into topics, we can obtain the relevant business information
- Each topic also has a maximum of 3 layers
- Usage of mapping to map different domains
- Cons:
- Increased Complexity: Organizing models into different business domains can add complexity to the system, making it harder to manage and understand.
- Complex Business Logic: Implementing and maintaining complex business logic within each domain requires significant effort and expertise.
- Coordination Challenges: Mapping and integrating different domains can be challenging, leading to potential issues in data consistency and communication between domains.
- Scalability Issues: As the number of domains grows, managing and scaling the system efficiently can become more difficult.
Lazada
Microservice (planned)
- Security and Audit: Easier to handle security and audit requirements with partners (for address unmasking)
- Scalability: microservice can be scaled independently to satisfy audit solutions.
- Fault Isolation: Failures in one service don’t affect others and main workflow
Problem:
- Communication Overhead: Increased costs due to having to support data contracts and more table to integrate microservice into workflow
Conclusion
Why Different Architectures for Each Application? Each architecture is optimised for specific requirements:
- CRM uses MVC for rapid user/employee interaction handling.
- Fulfilment relies on orchestration for reliable (wrong data costs), high-volume data exchanges.
- Event-driven architectures are reserved for processes where delay is critical and requires 100% data is processed.
- Data warehouses use layering and DDD to manage complex datasets effectively.
In reality, all the different architecture styles are not used in isolation of one another. This can be seen in our data warehouse where a combination of multiple styles are used such as layering, orchestration and DDD.
As the business grows it is likely that the data warehouse will further split into different data layers so that there can be better segmentation of the different data. Some possible examples would be that fct and aggregated layers could be migrated to new schemas.

