

Hot Product
Guide to migration from 1:1 to 1:M
What is 1 to 1 and 1 to M relationship for data warehouse:
One-to-One (1-to-1) Relationship
Definition: A one-to-one relationship in a data warehouse means that each record in one table corresponds to exactly one record in another table.
Example: Suppose you have two tables: orders and order_shipping, where each order has a unique set of shipping details that don’t apply to any other order.
Orders Table:
|
order_id |
order_date |
customer_id |
|
1 |
2024-07-01 |
101 |
|
2 |
2024-07-02 |
102 |
Order Shipping Table:
|
order_id |
shipping_address |
payment_method |
|
1 |
123 Main St |
Credit Card |
|
2 |
456 Elm St |
PayPal |
In this case, there is a one-to-one relationship between the orders table and the order_shippingtable, as each order has exactly one set of details, which means there cannot be another row of order_id = 2 in the order_shipping table. Each record in the orders table has exactly one corresponding record in the order_shipping table.
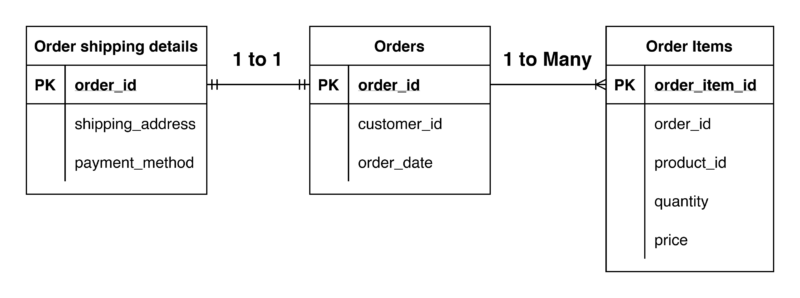
One-to-Many (1-M) Relationship
Definition: A one-to-many relationship in a data warehouse means that each record in one table can be associated with multiple records in another table.
Example: Suppose you have two tables: orders and order_items, where each order can include multiple products.
Orders Table:
|
order_id |
order_date |
customer_id |
|
1 |
2024-07-01 |
101 |
|
2 |
2024-07-02 |
102 |
Order Items Table:
|
order_item_id |
order_id |
product_id |
quantity |
price |
|
1 |
1 |
201 |
2 |
25.00 |
|
2 |
1 |
202 |
1 |
50.00 |
|
3 |
2 |
203 |
3 |
15.00 |
In this case, there is a one-to-many relationship between the orders table and the order_items table, as each order can include multiple items.
Why are currently Vatico is using mainly 1-to-1
Fast Development:
- Simplicity: 1-to-1 relationships are simpler to implement and manage, which can significantly speed up development. Developers don’t need to handle complex join operations or manage data integrity issues that arise with 1-to-M relationships.
- Reduced Complexity: With fewer tables and simpler relationships, the development process is streamlined, and the potential for errors is minimised.
Fewer Tables:
- Simplicity in Schema Design: With 1-to-1 relationships, you typically have fewer tables. For example, handling invoices with 1-to-1 relationships might involve just a couple of tables: invoices and invoice_details, invoice_items_details can be absorbed in invoice_details instead of standalone table
- Easier Management: Managing fewer tables simplifies database administration, data maintenance, and query formulation. Table can be reduce twice as much compare to 1-to-M models
No Dimensional Modelling:
- Quick Implementation: By avoiding complex dimensional modelling, Vatico could quickly move from manual processes to automated ones without needing to design a normalised data schema from scratch.
However, 1-to-1 has many shortcomings:
- Limited Complexity: Cannot efficiently handle scenarios where entities naturally have multiple related records, such as orders with multiple SKUs, leading to constrained data representation.
- Redundancy and Maintenance: Often results in data redundancy and increased maintenance complexity, as data may need to be duplicated or managed across multiple 1-to-1 tables.
- Scalability Issues: As the business grows, the simplistic 1-to-1 model becomes inadequate, struggling to support more complex relationships and larger datasets. For example, warranty upgrade invoices require 2 items per invoice, which is not supported among our 1-to-1 models. In the future if some other business service require 3 or 4 items per invoice, this will really constraints the current 1-to-1 models
Hence, we need 1-to-M models for Future Scalability
Most of the benefits of the 1-to-1 model focus on quick deployment, development and at a smaller scale. However, to grow our business, making the data pipeline more adaptable and handle more data, we need to shift to using 1-to-M models. Below are schemas we can follow for this migration.
Normalised vs Denormalised Schema
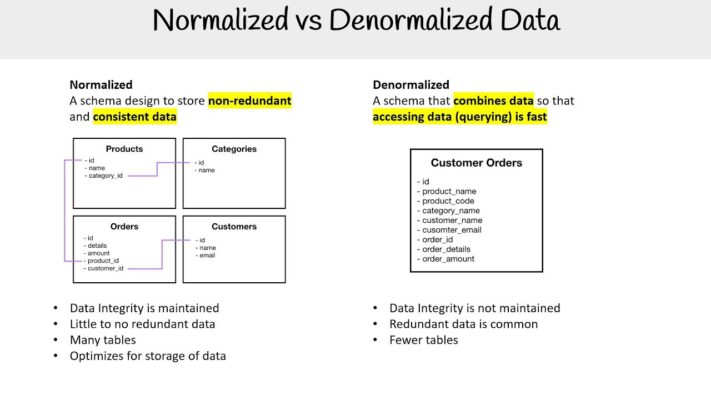
1. Denormalized Tables
Definition: Denormalization is the process of combining normalised tables into fewer, larger tables to improve read performance and simplify query structures. This approach intentionally adds redundancy to the database. Commonly used in Kimball. This is the approach we are taking in Vatico.
Current Implementation in Vatico of current denormalized table and Kimball:
- ODS Connection:
- The Operational Data Store (ODS) currently connects with an in-house ingestion framework, handling ETL processes to ensure accurate data integration. The ods layer is currently the staging layer
- Future transition to modern ETL Tools: Transitioning to Airbyte and Fivetran will automate and streamline data ingestion, offering scalable and reliable data pipelines.
-
Data Access and Exposure
- API and Dashboards:
- The Analytical Data Store (ADS) will expose data via APIs or dashboards using Looker Studio, providing real-time access and visualisation. These tables are currently mainly denormalized table
- Denormalized Data in DWS
- DWS Consumption: The Data Warehouse (DWS) will consume denormalized data from dimension (dim) and fact (dwd) tables. This follows the Kimball methodology: Dimension tables provide context, while fact tables store quantitative data, forming a star schema.
Pros:
- Improved Read Performance: Fewer joins result in faster query execution.
- Simplified Queries: Consolidated data makes queries easier to write and understand.
Cons:
-
- Increased Data Redundancy: Data duplication leads to higher storage costs and potential inconsistencies.
- Complex Updates: Changes must be made in multiple places, increasing the risk of data anomalies. We need to trace the upstream of the piece of information to change it.
- Hard to test: denormalized are hard to test due to many components
2. Normalised Tables
Definition: Normalisation is the process of organising data to reduce redundancy and improve data integrity. This involves dividing a database into two or more tables and defining relationships between them. Commonly used in Immon. There are 3 layers of normalisation: Read more
Normalisation in Vatico is not truly done before as we previously only support one to one relationship which does not require normalisation that much.
Pros:
- Reduced Data Redundancy: Each piece of data is stored only once.
- Improved Data Integrity: Ensures consistency and accuracy through constraints and relationships.
- Simplified Maintenance: Changes are made in one place, reducing the risk of anomalies.
Cons:
-
- Hard to scale: If all tables are to be normalised, it will be lacks in foundation, connections between models and hard to scale.
- Complex Queries: Often requires joins between multiple tables, which can slow down performance.
- Development Overhead: Increased complexity in unit testing and data validation.
- Heavy load: Normalised models usually support 1-to-Many relationships, with a constraint to read as an API interface.
However
Normalisation versus denormalisation can be treated as a spectrum: We do not strictly choose to be either, but some models can be more normalised or less normalised depending. We can actually leverage the strength of both schema types by using a combination of both.
Denormalised x Normalised with data layers
Definition: This approach uses denormalized tables at the lower, operational level (downstream) for fast, simplified access, and normalised tables at the higher, integration level (upstream) to ensure data integrity and consistency.
Example: A combination of denormalised and normalised approach can be seen from the warranty replacement invoice process. There is:
- Upstream denormalized invoice level only info model: invoice_warranty_replacement_daily_api_to_issue
- Upstream more normalised item level only info model: invoice_warranty_replacement_daily_items_api
- An downstream ads table that combine both table and acts as API interface for orchestration: ads_invoice_warranty_replacement_daily_api_to_issue_with_xml
Pros:
- Balanced Approach: Combines benefits of both normalisation and denormalization.
- Optimised Performance: Denormalized tables downstream for fast access; normalised tables upstream for data integrity.
- Comprehensive Handling: Suitable for complex scenarios with multiple SKUs and ensures data accuracy via data contracts (formatted XML or JSON).
Cons:
- Implementation Complexity: Requires careful planning and management of data layers.
- Data Processing Overhead: Additional processing to transform data between layers.
We can see that changing to Denormalised x Normalised with data layers is the right approach to resolve the current problem of mainly using denormalized tables and supporting migration to one-to-many relationships.
Application
Invoice Automatic Issue Process:
Current State:
- The current sales invoice process supports only one item per invoice due to a previously implemented 1-to-1 relationship, leading to highly denormalized tables.
- For example, the invoice_daily_api_to_issue model contains both invoice and item information at the invoice level.
Problem:
- For adjustment invoices created from business services like warranty upgrades or warranty replacements, we need to support multiple items per invoice.
- To address this, we are transitioning to a more normalised approach.
Approach:
- Normalisation:
- Objective: Reduce redundancy and establish relationships between tables.
- Models:
- invoice_warranty_replacement_daily_api_to_issue: An upstream denormalized model containing invoice-level information. (1-to-1 relationship)
- invoice_warranty_replacement_daily_items_api: An upstream normalised model containing item-level information. (1-to-Many relationship)
- Process:
- Separate and process the two models individually.
- Establish a 1-to-Many relationship between the models by joining on woo_id.
- Denormalization for API Interface:
- Objective: Simplify orchestration queries by providing a denormalized view.
- Model:
- ads_invoice_warranty_replacement_daily_api_to_issue_with_xml
- Process:
- Join the normalised tables to create a denormalized table.
- This denormalized table allows the orchestration to easily query and handle invoices with multiple items.
Summary:
- We are shifting from a denormalized single-item invoice model to a normalised multi-item invoice model.
- This involves normalising the invoice and item information into separate upstream tables and then denormalizing them again for API interface purposes.
- This approach balances the need for normalisation during processing and the efficiency of denormalized data for API interactions.
Good Denormalized x Normalised with data layers schema (for future migration):
Normalisation at the ADS Layer
- Impact at ADS: The ADS layer will now prioritise normalised data with proper data contracts. DA must be mindful of the level of normalisation and handle correct dimensions of the ADS table now.
- Data Contracts: Establish clear data contracts to define the structure and constraints of the data. This is crucial for applications and analytics to adapt to ever-changing requirements.
Unchanged Layers (ODS and DWD)
- Ingestion (ODS): The ODS layer remains unchanged, continuing to use the in-house framework for data ingestion. No Data Engineering (DE) work is required here.
- Data Warehouse (DWD): The DWD layer will still utilise denormalized data structures (dim and fact tables) as per the Kimball methodology. Data Analysts (DA) can continue to work with this setup without modifications.
Challenge of migration to Denormalized x Normalised with data layers
- Recipe Creation: In the old approach, the initial step involves creating the “recipe” or the raw data (ingredients) in the Transformation (T) layer. In the new design, the transformation step is removed from the orchestration layer. Instead, the focus shifts to enforcing strict data contracts at the Transformation (T) layer.
- Enforcing Data Contracts: The T layer must now ensure that all data adheres to predefined contracts, which means the data needs to be accurate and complete before it reaches the orchestration layer. This can be challenging as the T layer lacks the orchestration layer’s extensive testing capabilities.
- Costly: this requires extensive collaboration between DE and DA, hence waste resources.
- Soap API approach:
- Complex Data Input: SOAP APIs typically accept complex data structures as input, which are then processed by partners. Ensuring these inputs meet strict data contracts can be difficult without extensive testing. For example date need a specific format
- Generic Error Message: If API is not carefully engineered, error returns are too generic to debug, causing problem for DE and DA
- Industry Norm: to fulfil data contract with a xml template and build up system fulfil that xml template. However, this costs a lot of time and careful documentation.

